
https://www.yuque.com/ripic/zb2dv9/ggnsyl4l4o6a2syi?singleDoc# 《VLLM && CNB》

假设我们发现了一个函数 f(x):
f("小红有3个苹果,给了小明1个,还剩几个?") = "2个"f("我真是谢谢你们的服务,烤冷面外卖送到的时候真成了冷面。这句话是正面还是负面评价?") = "负面"f("你真帅。这句话是正面还是负面评价?") = "正面"
那就认为,对这两个例子来说,函数 f(x) 就是机器学习要找的函数。
那么难点来了,怎么找到这个函数呢?
我们降低一下目标,把要找的函数设定为 y = 3x,即我们要找一个函数 f(x),<font style="color:rgb(31, 35, 40);background-color:rgba(129, 139, 152, 0.12);">f(1) = 3</font>,<font style="color:rgb(31, 35, 40);background-color:rgba(129, 139, 152, 0.12);">f(2) = 6</font>,<font style="color:rgb(31, 35, 40);background-color:rgba(129, 139, 152, 0.12);">f(10) = 30</font>。
有人会说这不简单吗,y = 3x。
嗯,别急,我们此时还不知道答案呢,或者当问题变得非常复杂时,靠人脑根本找不到函数的表达式时,怎么样才能让函数寻找得以继续?
<font style="color:rgb(31, 35, 40);">Define model function -> Define loss function -> Optimization</font>
第一步:Define model function
就是定义函数,这可不是一步到位定义函数,而是定义一个具有任意数量未知参数的函数骨架,我们希望通过调整参数的值来逼近最终正确函数。
假设我们定义一个简单的一元一次函数:
其中未知参数是 w 和 b,也就是我们假设最终要找的函数可以表示为 b + wx,但具体 w 和 b 的值是多少,是需要寻找的。
我们可以这么定义:
const modelFunction = (b: number, w: number) => (x: number) => {
return b + w * x;
};
其中 w 表示 weights(权重),b 表示 bias(偏移),对这个简单的例子比较好理解。这样对于每一组 w 和 b,都能产生一个唯一的函数。
你也许会觉得,一元一次函数根本不可能解决通用问题。对,但为了方便说明机器学习的基本原理,我们把目标也设定为了简单的 y = 3x。
第二步:Define loss function
就是定义损失函数,这个损失可以理解为距离完美目标函数的差距,可以为负数,越小越好。我们需要定义 loss 函数来衡量当前 w 与 b 的 loss,这样就可以判断当前参数的好坏程度,才能进入第三步的优化。因此 loss 函数的入参就是第一步 model function 的全部未知参数:w 与 b。
有很多种方法定义 loss 函数,一种最朴素的方法就是均方误差:
即计算当前实际值 <font style="color:rgb(31, 35, 40);background-color:rgba(129, 139, 152, 0.12);">modelFunction(b,w)(x)</font> 与目标值 <font style="color:rgb(31, 35, 40);background-color:rgba(129, 139, 152, 0.12);">3x</font> 的平方差。那么 loss 函数可以这样定义:
const lossFunction = (b: number, w: number) => (x: number, y: number) => {
const cy = modelFunction(b, w)(x);
return Math.pow(y - cy, 2);
};
上述函数在给定 w 与 b 的下,计算在某个 training data 下的 loss,在调用处遍历所有 training data,把所有 loss 加起来,就是所有 training data 的 loss 总和。
为了让寻找的函数更准确,我们需要想办法让 loss 函数的值最小。
第三步:optimization
optimization 就是优化函数的参数,使 loss 函数值最小。

那么代码如下:
const optimization = (b: number, w: number) => (x: number, y: number) => {
const gradB = -2 * (y - modelFunction(b, w)(x));
const gradW = -2 * x * (y - modelFunction(b, w)(x));
return { gradB, gradW };
};
接着我们就可以使用 training data 开始训练,不断更新参数 w 与 b 的值,直到 loss function 的值下降到极限,就可以认为训练完毕啦。
训练有三种方式使用偏导数,随机梯度下降、批量梯度下降与小批量梯度下降。它们的区别仅在于什么时候真正更新 w 与 b。
- 随机梯度下降:对每一个 training data 项都立刻更新 w 与 b。
- 批量梯度下降: 对所有 training data 都计算出 w 与 b,最后取平均值一次更新,之后再进入下一轮递归。
- 小批量梯度下降:对 training data 取一个 batch size,达到 batch size 后立刻更新 w 与 b。
代码实践
const trainingData = [[1, 3],[2, 6],[3, 9],[4, 12],[5, 15]];
let b = initB; let w = initW;
function train() {
let gradBCount = 0;let gradWCount = 0;
trainingData.forEach((trainingItem) => {
const { gradB, gradW } = optimization(b, w)(
trainingItem[0], trainingItem[1]);
gradBCount += gradB;gradWCount += gradW;});
b += (-gradBCount / trainingData.length) * learningRate;
w += (-gradWCount / trainingData.length) * learningRate;
}
// 训练 500 次
for (let i = 0; i < 500; i++) {train()}

实际操作:https://dp.333.zone
开始之前,我们先进性一轮数学推导,对于一个单节点的神经网络而言
:输入特征;对应的权重。:偏置。:线性输出(激活前的值)
还可以写成矩阵的形式
拓展到多神经元:
- 神经元 1:
- 神经元 2:
- 神经元 3:
显然:
加上激活函数之后:,这里的 是对向量中的每个元素分别进行操作。
最常见的通用公式如下:
麻烦的加减乘除运算替换成了矩阵运算,可以充分利用GPU的运算能力。http://www.blackbox.ai/
| 特性 | 全连接层 | 卷积层 |
|---|---|---|
| 基本操作 | 矩阵乘法 ( ) | 卷积运算 ( ) |
| 连接方式 | 全局连接 (每个输入连每个输出) | 局部连接 (只看局部区域) |
| 权重共享 | 无 (每个位置权重独立) | 有 (同一个核在图上滑动,权重共用) |
| 适用场景 | 分类器末端,处理抽象特征 | 特征提取端,处理图像/语音/文本 |
| 数据维度 | 1D 向量 | 3D 张量 (高, 宽, 通道) |
卷积核:https://setosa.io/ev/image-kernels/
数字识别与可视化(卷积->池化(降维)):https://adamharley.com/nn_vis/cnn/3d.html
文字向量化:https://ronxin.github.io/wevi/ https://projector.tensorflow.org/
文字关联度
- 向量
- 向量
点积
点积直接计算两个向量在对应维度上的乘积之和。它既考虑了方向,也考虑了向量的长度(模长)。如果两个向量的值都很大且方向一致,点积会非常大。
公式:
或者用矩阵转置表示:
注意: 在深度学习的注意力机制(如 Transformer)中,经常直接使用点积来衡量关联度,但为了稳定梯度,通常会除以 进行缩放。
余弦相似度
余弦相似度通过计算两个向量夹角的余弦值来衡量相似度。它只关注向量的方向是否一致,而忽略了向量的绝对长度(即归一化了模长的影响)。取值范围通常在 -1 到 1 之间。
公式:
展开后的详细公式为:
其中:
- 分子是两个向量的点积。
- 分母是两个向量的欧几里得范数(模长)的乘积。
回顾前馈神经网络的公式:
然后通常接一个非线性激活函数 ,得到:
这是标准的前馈网络,信息单向流动,无记忆。
在序列建模中(如文本、语音、时间序列),我们希望网络具有“记忆”能力,即当前输出不仅依赖当前输入,还依赖过去的状态。
设:
- :时刻 的输入;:时刻 的输出(可选)。
- :时刻 的隐藏状态(hidden state),可视为网络的“记忆”;
RNN 的核心思想是:将上一时刻的隐藏状态 作为当前时刻的额外输入。
因此,在计算当前时刻的隐藏状态时,我们同时考虑:
当前输入 ;上一时刻的隐藏状态
类比前馈网络的公式,我们将 替换为两个输入的拼接(或分别加权后相加):
其中:
- :输入到隐藏层的权重矩阵;:隐藏层到自身的循环权重矩阵(体现“循环”);
- :偏置项;:时刻 的加权输入。
然后应用非线性激活函数(常用 tanh 或 ReLU):
这就是基本 RNN 的隐藏状态更新公式。
若需要输出 ,可再加一个输出层:
其中:
- :隐藏层到输出的权重;
- :输出偏置;
- :输出激活函数(如 softmax 用于分类)。
其中初始状态 通常设为零向量或可学习参数。
对比原始公式 ,RNN 相当于在每个时间步 上,将“前一层”扩展为两个来源:
- 外部输入 ;
- 自身历史状态 。
这种结构使得网络在时间上展开后形成一个深层网络(称为“通过时间的反向传播”,BPTT),但参数 在所有时间步共享,从而具备处理变长序列的能力。
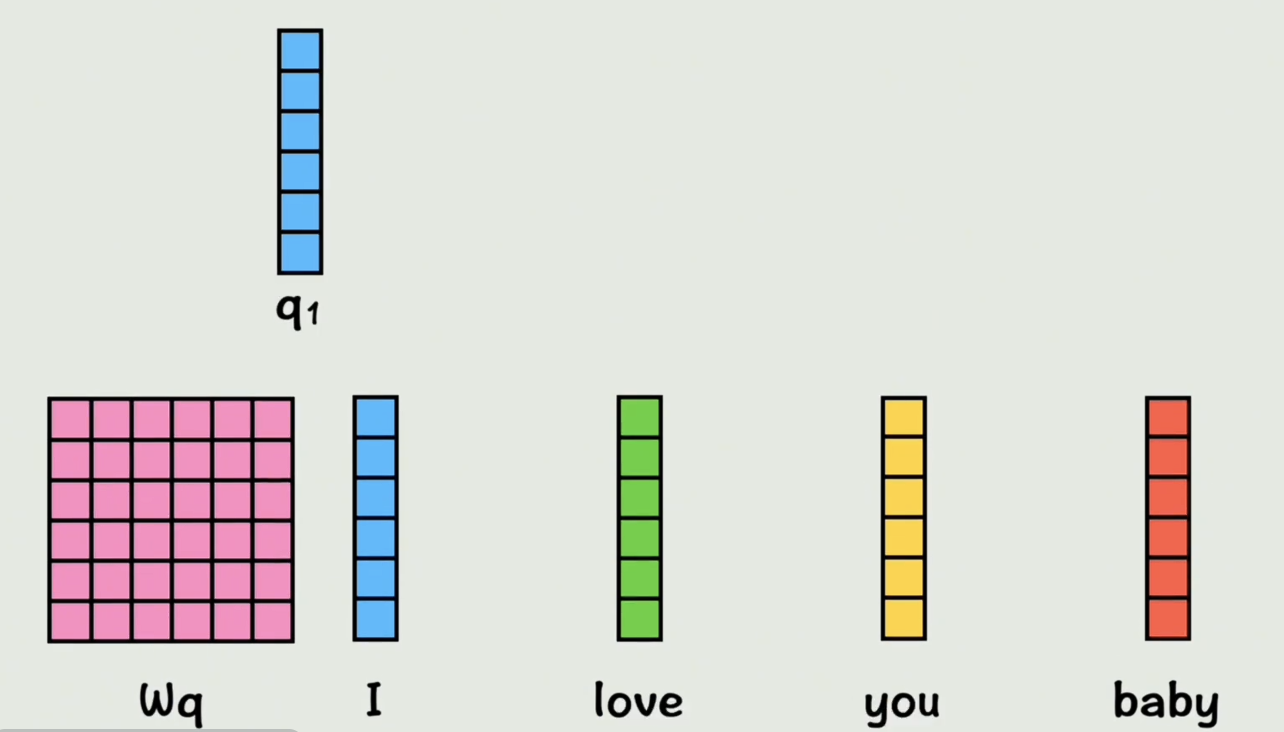
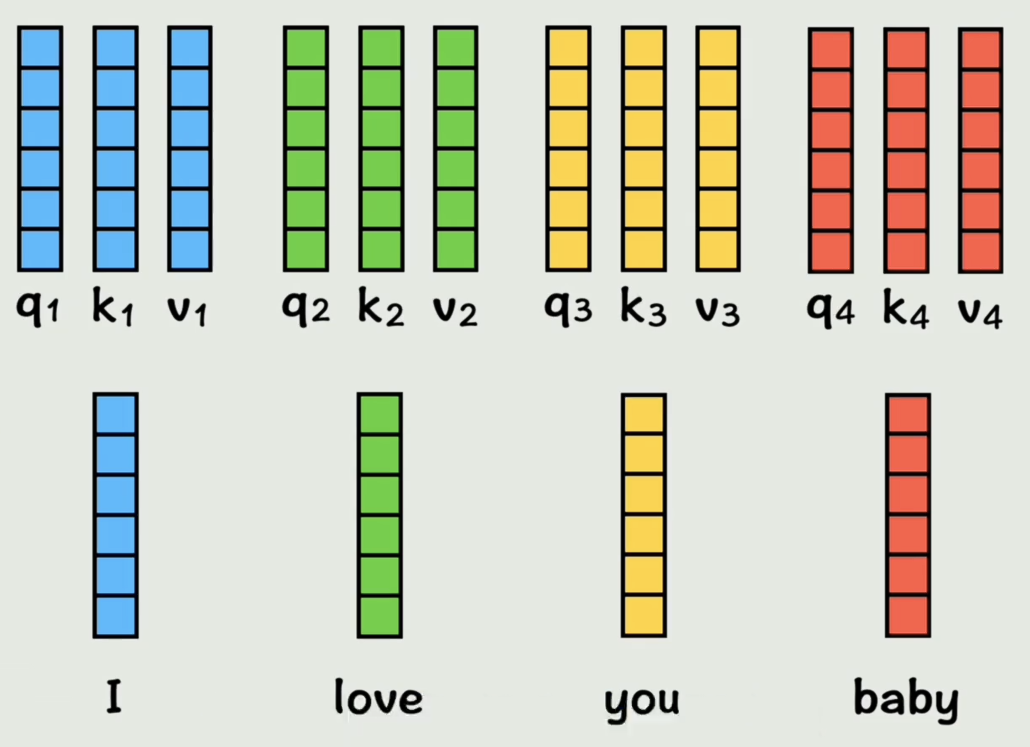
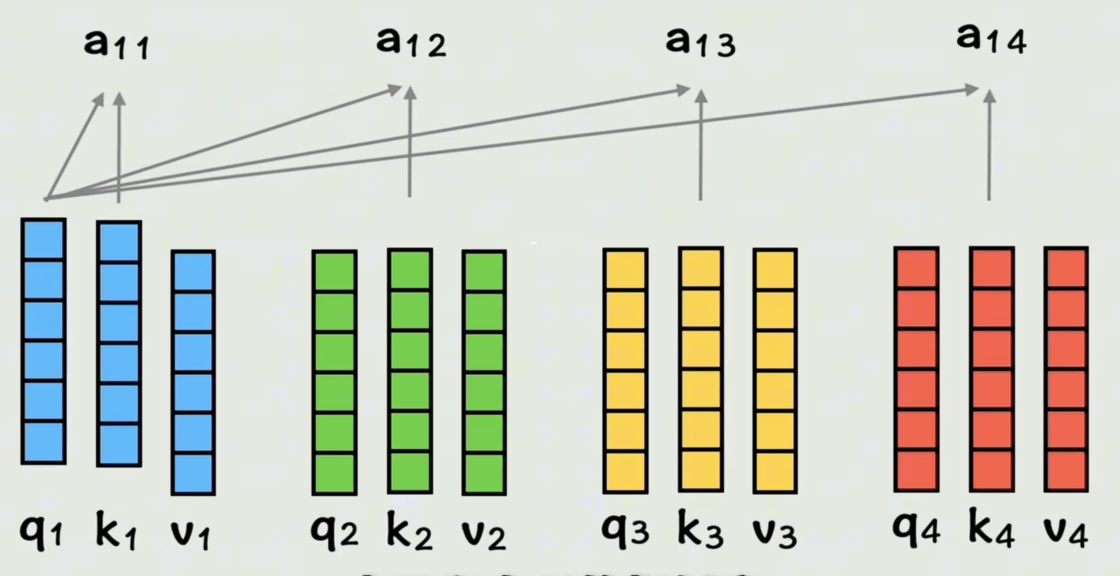
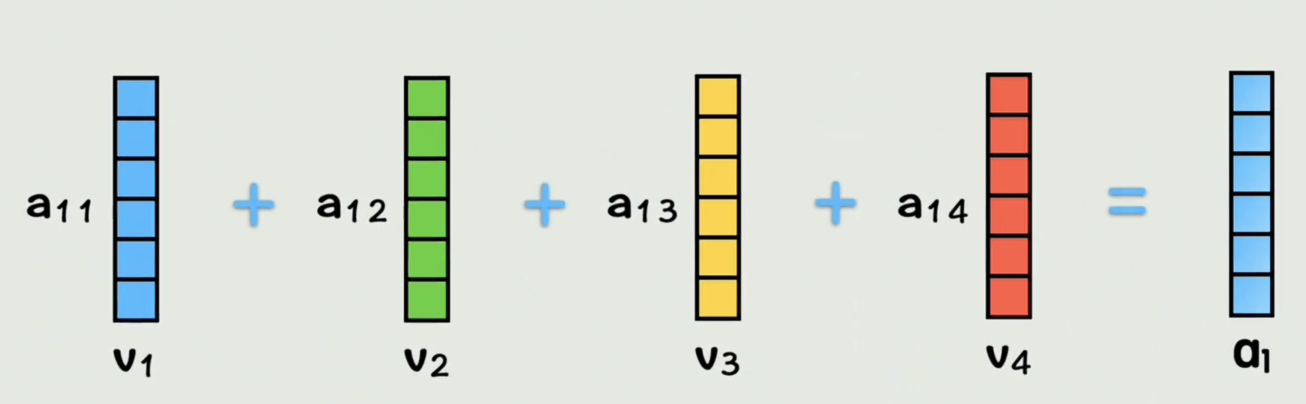
上面省略了缩放、掩码和softmax(归一化)运算


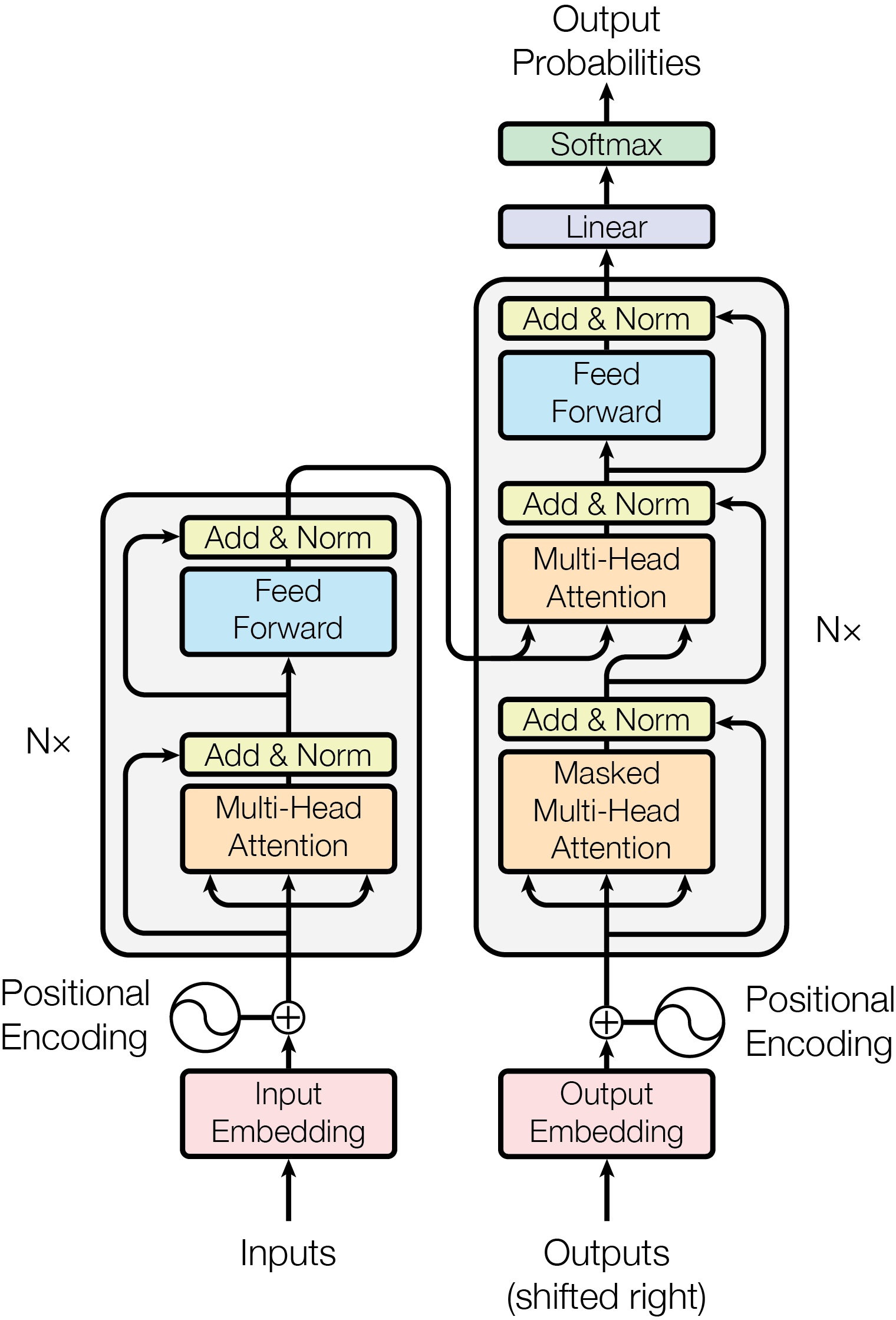
在此基础上增加残差网络和归一化处理,避免梯度消失,在连接上前馈神经网络

LLM 服务的性能瓶颈在于内存(显存)。在自回归解码autoregressive decoding过程中,LLM 的所有输入tokens都会产生其注意键和值张量attention key and value tensors,这些张量保存在 GPU 内存中以生成下一个tokens。这些缓存的键和值张量通常称为 KV 缓存(KV cache)。KV 缓存有如下特点:
- 大:LLaMA-13B 中单个序列占用高达 1.7GB 的空间。
- 动态:其大小取决于序列长度,而序列长度变化很大且不可预测。因此,有效管理 KV 缓存是一项重大挑战。我们发现现有系统由于碎片化和过度预留而浪费了 60% - 80% 的内存。
为了解决这个问题,vLLM引入了 PagedAttention,这是一种注意力算法,其灵感来自操作系统中虚拟内存和分页的经典思想。与传统的注意力算法不同,PagedAttention 允许在非连续的内存空间中存储连续的键和值。具体来说,PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量 token 的键和值。在注意力计算过程中,PagedAttention 内核会高效地识别和获取这些块。
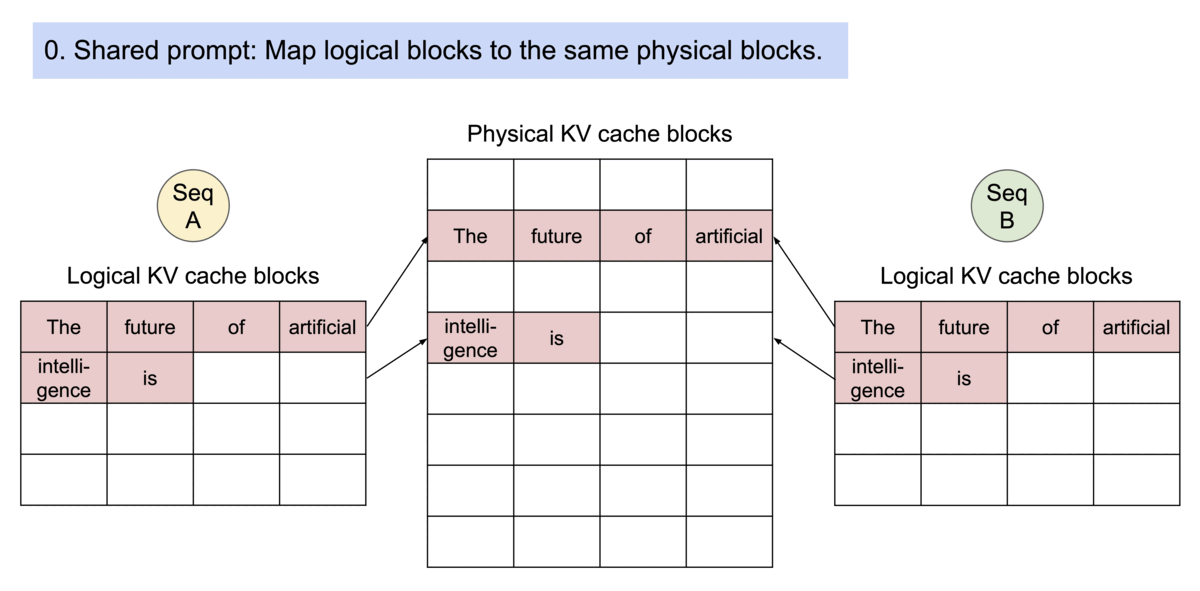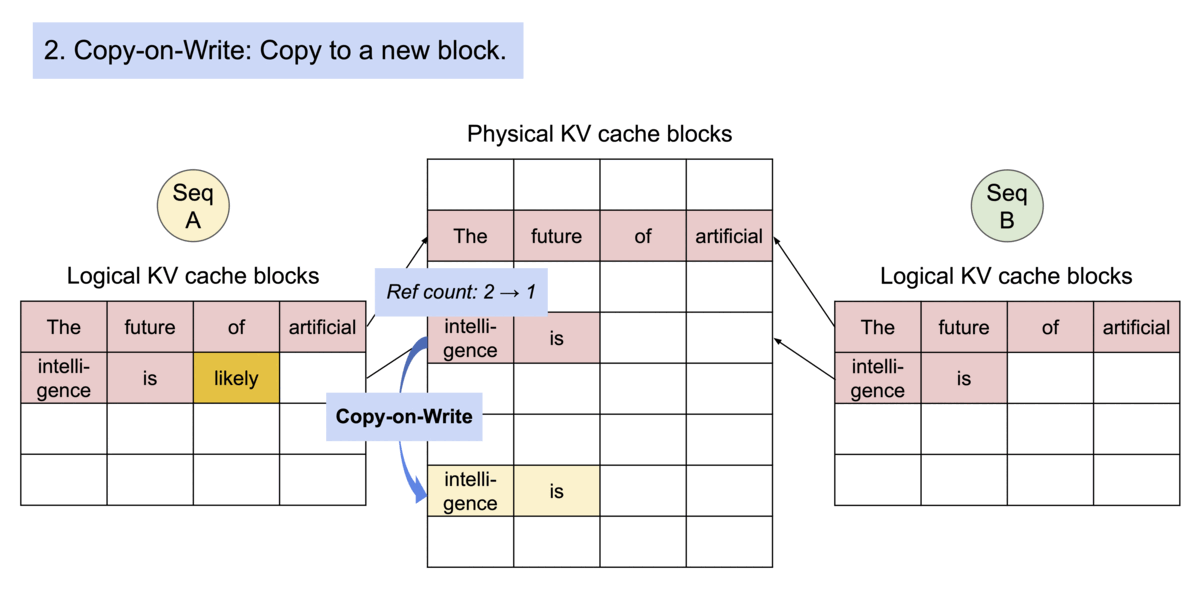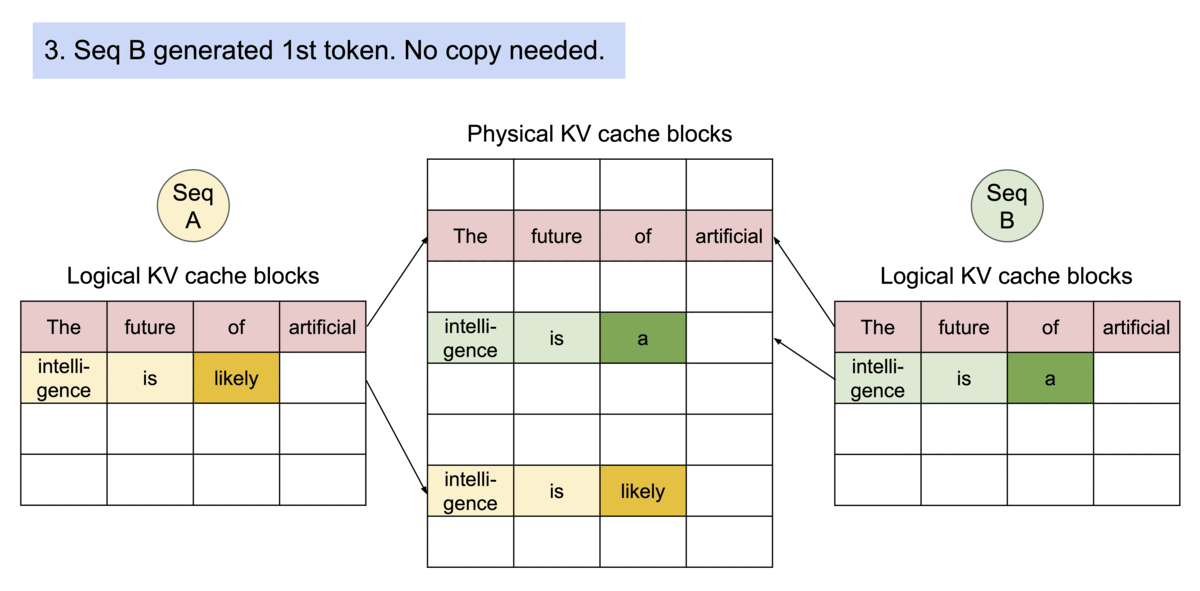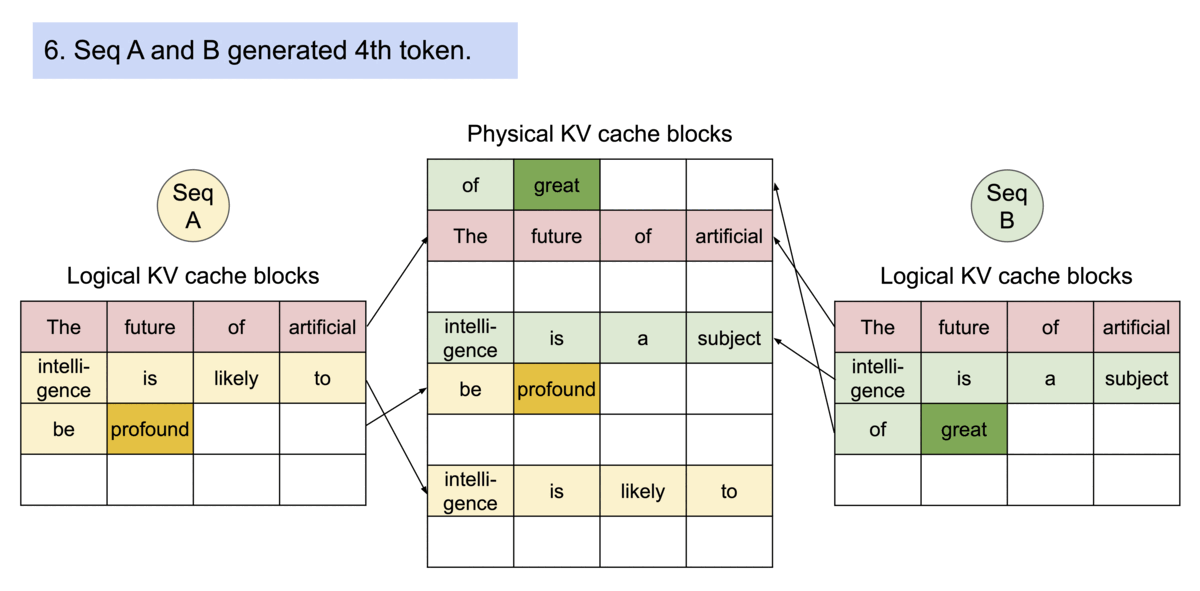
PagedAttention 通过其块表自然地实现了内存共享。与进程共享物理页面的方式类似,PagedAttention 中的不同序列可以通过将其逻辑块映射到同一物理块来共享块。为了确保安全共享,PagedAttention 会跟踪物理块的引用计数并实现写时复制机制。
PageAttention 的内存共享功能大大降低了复杂采样算法(例如parallel sampling和beam search)的内存开销,最多可减少 55% 的内存使用量。这可以转化为高达 2.2 倍的吞吐量提升。这使得此类采样方法在 LLM 服务中变得实用。
材料和参考资料稍晚更新到代码仓库