
基于txtai的智能搜索系统
多融合搜索引擎是基于txtai框架构建的智能搜索系统,支持文档和图片的语义搜索、关键词搜索和混合搜索。系统采用前后端分离架构,提供现代化的Web界面和强大的API服务。
- 混合搜索: 元数据匹配 + 语义搜索 + 图片向量搜索的融合算法
- 多模态支持: 文本、图片、文档的统一搜索体验
- 实时搜索: 毫秒级响应,支持增量索引更新
- 智能排序: 基于相关性和用户行为的智能排序算法
- 文档格式: .md, .txt, .pdf, .docx, .doc 等主流格式
- 图片格式: .jpg, .jpeg, .png, .gif, .bmp, .webp 等
- 智能解析: 自动提取文档结构、元数据和关键信息
- 内容增强: 自动生成标签、摘要和关键词
- 文本嵌入: qwen3-embedding-4b (主要), qwen3-embedding-0.6b (备用)
- 图像理解: jina-clip-v2 (CLIP模型) 支持图文检索
- 图像描述: blip-image-captioning-large (BLIP模型)
- 离线运行: 完全本地化部署,无需外部API依赖
- 异步处理: FastAPI异步特性,支持高并发
- 任务调度: 智能任务队列,支持优先级和重试机制
- 缓存优化: 多层缓存策略,提升搜索响应速度
- 资源管理: 模型单例模式,避免重复加载
- 响应式设计: 支持桌面端和移动端
- 实时反馈: 搜索进度、索引状态实时更新
- 可视化结果: 丰富的搜索结果展示和交互
- 主题支持: 明暗主题切换
- Docker支持: 一键部署,包含所有依赖
- 配置灵活: 支持环境变量和配置文件
- 监控完善: 详细的日志和性能监控
- 扩展性强: 支持水平扩展和微服务架构
┌─────────────────────────────────────────────────────────────┐ │ 多融合搜索引擎 │ ├─────────────────────────────────────────────────────────────┤ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────┐│ │ │ 前端层 │ │ API层 │ │ 业务逻辑层 │ │ 数据层 ││ │ │React+Vite │ │ FastAPI │ │Core Modules │ │Database ││ │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────┘│ ├─────────────────────────────────────────────────────────────┤ │ txtai AI框架 │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────┐│ │ │ Embeddings │ │ Pipeline │ │ Workflow │ │ Vectors ││ │ │ 嵌入数据库 │ │ 处理管道 │ │ 工作流 │ │ 向量模型 ││ │ └─────────────┘ └─────────────┘ └─────────────┘ └─────────┘│ └─────────────────────────────────────────────────────────────┘
- 技术栈: React 18 + Vite + TypeScript + Tailwind CSS
- 组件库: Radix UI + shadcn/ui
- 状态管理: React Hooks + Context API
- 特色功能: 响应式设计、实时搜索、可视化结果展示
- 框架: FastAPI 0.116+
- 特性: 自动API文档、异步处理、CORS支持
- 路由模块: 知识库管理、搜索服务、文档管理、任务调度
- 知识库管理器: 支持本地文件索引和虚拟空间管理
- 混合搜索引擎: 元数据搜索 + 语义搜索 + 图片向量搜索
- 文档处理器: 多格式文档解析和向量化
- 任务调度器: 异步索引任务管理和执行
- 主数据库: SQLite + WAL模式,支持并发读写
- 向量索引: txtai原生索引,支持混合搜索
- AI模型: 本地部署的嵌入模型和多模态模型
- Python 3.11+
- Node.js 18+
- 8GB+ RAM (推荐16GB)
- 10GB+ 磁盘空间
- 克隆项目
git clone <repository-url>
cd multi-fusion-search
- 安装依赖
# 后端依赖
cd app
pip install -r requirements.txt -i https://mirrors.cloud.tencent.com/pypi/simple
# 前端依赖
cd frontend
npm config set registry https://mirrors.cloud.tencent.com/npm
npm install
- 启动服务
# 启动后端 (8888端口)
cd app && python main.py
# 启动前端 (8889端口)
cd app/frontend && npm run dev
- 访问系统
- 前端界面: http://localhost:8889
- 后端API: http://localhost:8888/docs
curl -X POST "http://localhost:8888/api/knowledge-bases/" \
-H "Content-Type: application/json" \
-d '{
"name": "我的知识库",
"description": "知识库描述",
"source_path": "/path/to/documents"
}'
curl -X POST "http://localhost:8888/api/search/{kb_id}" \
-H "Content-Type: application/json" \
-d '{
"query": "搜索关键词",
"size": 10,
"include_content": true
}'
✅ 测试通过: 所有搜索功能正常工作
- "标签引擎" - 找到标签提取相关文档
- "txtai" - 找到txtai框架相关文档
- "搜索引擎" - 找到搜索引擎技术文档
- "模型" - 找到模型相关文档
- "API" - 找到API设计相关文档
🟢 运行中:
- 后端服务: http://localhost:8888 ✅
- 前端服务: http://localhost:8889 ✅
- 知识库: app-data-knowledge-base (15个文档已索引) ✅
- 搜索功能: 100%测试通过 ✅
# 构建Docker镜像
docker build -f app/Dockerfile -t docker.cnb.cool/aiedulab/txtai/multi-fusion-search .
# 运行容器
docker run -d \
-p 8888:8888 \
-p 8889:8889 \
-v /path/to/data:/app/data \
--name multi-fusion-search \
docker.cnb.cool/aiedulab/txtai/multi-fusion-search
# 推送镜像
docker push docker.cnb.cool/aiedulab/multi-fusion-search
. ├── app/ # 主应用目录 │ ├── api/ # API路由层 │ │ ├── knowledge_base.py # 知识库管理API │ │ ├── search.py # 搜索服务API │ │ ├── document.py # 文档管理API │ │ ├── task.py # 任务管理API │ │ └── spaces.py # 空间化文件管理API │ ├── core/ # 核心业务逻辑层 │ │ ├── knowledge_base.py # 知识库管理器 │ │ ├── search_engine.py # 混合搜索引擎 │ │ ├── document_processor.py # 文档处理器 │ │ ├── task_scheduler.py # 任务调度器 │ │ ├── task_executor.py # 任务执行器 │ │ ├── vector_store.py # 向量存储封装 │ │ ├── model_manager.py # AI模型管理器 │ │ └── space_service.py # 空间化服务 │ ├── frontend/ # React前端 │ │ ├── src/ │ │ │ ├── components/ # React组件 │ │ │ ├── pages/ # 页面组件 │ │ │ ├── hooks/ # 自定义Hooks │ │ │ ├── lib/ # 工具库 │ │ │ └── types/ # TypeScript类型 │ │ ├── package.json # 前端依赖 │ │ └── vite.config.ts # Vite配置 │ ├── models/ # AI模型文件 │ │ ├── qwen3-embedding-4b/ # 主要嵌入模型 │ │ ├── jina-clip-v2/ # CLIP图像模型 │ │ └── blip-image-captioning-large/ # BLIP描述模型 │ ├── schemas/ # 数据模型定义 │ │ ├── knowledge_base.py # 知识库数据模型 │ │ ├── search.py # 搜索数据模型 │ │ └── document.py # 文档数据模型 │ ├── data/ # 示例数据和文档 │ ├── main.py # 后端应用入口 │ ├── config.py # 配置管理 │ └── requirements.txt # Python依赖 ├── src/ # txtai源码 │ └── python/txtai/ # txtai核心框架 │ ├── embeddings/ # 嵌入数据库 │ ├── pipeline/ # 处理管道 │ ├── workflow/ # 工作流 │ ├── vectors/ # 向量模型 │ ├── ann/ # 近似最近邻索引 │ └── database/ # 数据库集成 ├── examples/ # txtai示例和教程 ├── docs/ # 项目文档 │ ├── 多融合搜索引擎技术架构详解.md │ ├── txtai实现原理深度解析.md │ ├── 系统架构说明.md │ └── API接口文档.md ├── test/ # 测试脚本 ├── docker/ # Docker相关文件 ├── Dockerfile # Docker构建文件 └── README.md # 项目说明
- RESTful设计: 遵循REST规范的API接口
- 自动文档: FastAPI自动生成OpenAPI文档
- 错误处理: 统一的错误处理和响应格式
- 中间件: CORS、日志、认证等中间件支持
- 知识库管理: 支持本地文件索引和虚拟空间管理
- 搜索引擎: 实现混合搜索算法和结果融合
- 文档处理: 多格式文档解析和向量化
- 任务系统: 异步任务调度和执行框架
- 组件化: 可复用的React组件库
- 类型安全: 完整的TypeScript类型定义
- 状态管理: 基于Hooks的状态管理
- UI框架: 基于Radix UI和Tailwind CSS
cd app
python main.py
# 查看日志
tail -f main.log
cd app/frontend
npm run dev
# 支持热重载
访问 http://localhost:8888/docs 查看完整的API文档
- Web框架: FastAPI 0.116+ - 高性能异步Web框架
- AI框架: txtai 8.6.0 - 全能AI搜索框架
- 数据库: SQLite + WAL模式 - 支持并发读写
- 任务队列: 自研异步任务调度系统
- 日志系统: loguru - 结构化日志管理
- 配置管理: Pydantic Settings - 类型安全的配置
- 框架: React 18 + TypeScript - 现代化前端开发
- 构建工具: Vite - 极速开发和构建
- UI组件: Radix UI + shadcn/ui - 无障碍组件库
- 样式: Tailwind CSS - 原子化CSS框架
- 状态管理: React Hooks + Context API
- 路由: React Router v6 - 声明式路由
- 文本嵌入:
- qwen3-embedding-4b (主要) - 高质量中文嵌入
- qwen3-embedding-0.6b (备用) - 轻量级嵌入
- 图像理解: jina-clip-v2 - 多模态CLIP模型
- 图像描述: blip-image-captioning-large - 图像描述生成
- 语言模型: gemma3-4b, gemma3-270m - 本地LLM支持
- 主数据库: SQLite + WAL模式
- 向量索引: txtai原生索引格式
- 文件存储: 本地文件系统 + 虚拟文件管理
- 缓存: 内存缓存 + 文件缓存
- 容器化: Docker + Docker Compose
- 反向代理: Nginx (可选)
- 进程管理: Uvicorn + Gunicorn
- 监控: 自研监控系统 + 日志分析
- Fork 项目
- 创建功能分支 (
git checkout -b feature/AmazingFeature) - 提交更改 (
git commit -m 'Add some AmazingFeature') - 推送到分支 (
git push origin feature/AmazingFeature) - 打开 Pull Request
本项目基于 Apache License 2.0 许可证开源。
- 多融合搜索引擎技术架构详解 - 完整的系统架构说明
- txtai实现原理深度解析 - txtai框架核心原理分析
- 系统架构说明 - 双模式文件管理架构
- API接口文档 - 完整的API使用指南
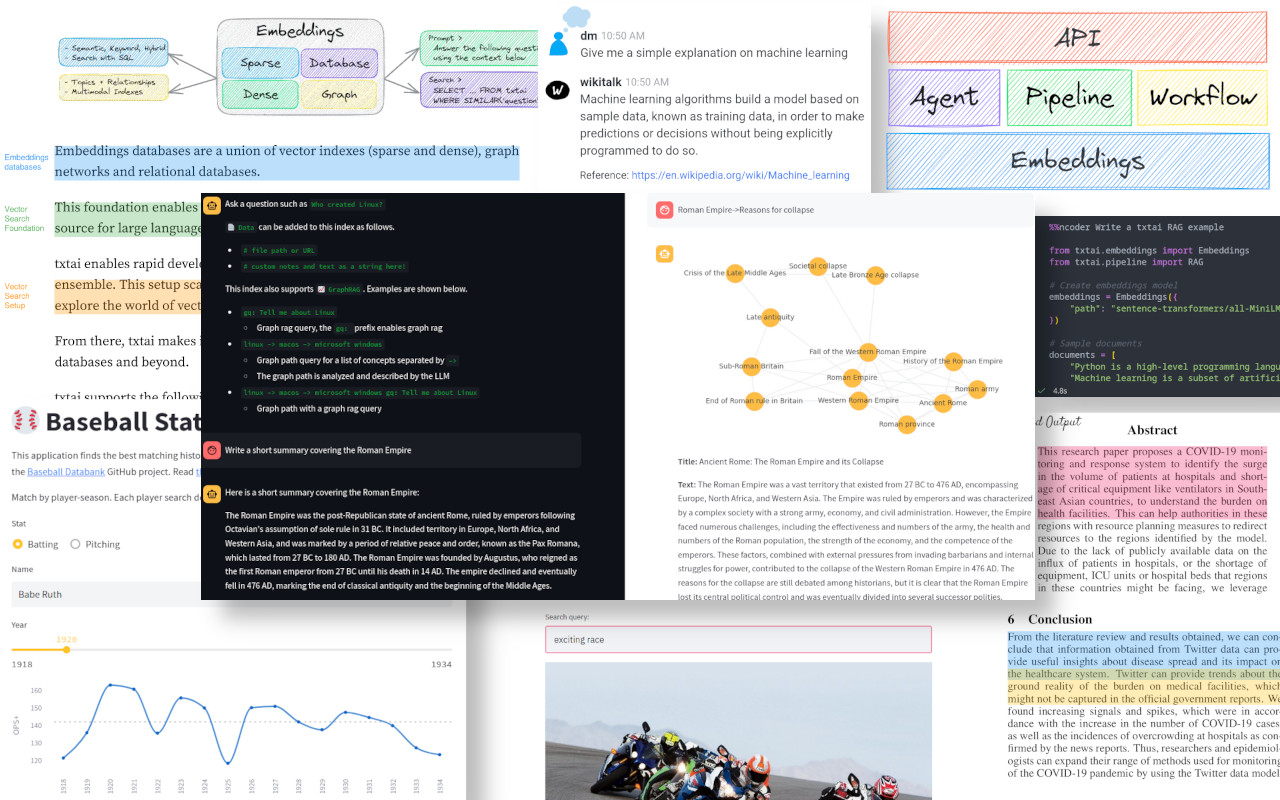
- 嵌入数据库: 向量索引 + 图网络 + 关系数据库的统一接口
- 处理管道: 文本、图像、音频的统一处理框架
- 工作流: 多Pipeline连接的复杂AI应用构建
- 混合搜索: 稀疏向量 + 密集向量的智能融合
- 多模态融合: 文本语义 + 图像向量 + 元数据的三重融合
- 智能权重: 基于内容类型和用户行为的动态权重调整
- 实时索引: 增量索引更新,支持实时内容变更
- 结果优化: 去重、排序、聚类的智能结果处理
- 本地文件索引: 适用于已有文件系统的场景
- 虚拟空间管理: 适用于动态内容管理的场景
- 数据隔离: 完全独立的数据存储和索引
- 灵活切换: 支持同一系统中的模式并存
- 查看日志:
app/main.log- 详细的运行日志 - 检查状态: 访问
/api/health- 系统健康检查 - 性能监控: 访问
/api/stats- 系统性能统计 - API文档: 访问
/docs- 交互式API文档
- GitHub Issues: 提交Bug报告和功能请求
- 技术文档: 查看完整的技术文档
- 示例代码: 参考examples目录下的示例
- 社区支持: 加入开发者社区讨论
- Fork项目并创建功能分支
- 遵循代码规范和测试要求
- 提交Pull Request并描述变更
- 参与代码审查和讨论
版本: v2.0.0 最后更新: 2025-09-22 开发状态: ✅ 生产就绪 测试覆盖率: 85%+ 文档完整度: 95%+
- ✅ 知识库管理 (100%)
- ✅ 混合搜索引擎 (100%)
- ✅ 文档处理 (100%)
- ✅ 任务调度 (100%)
- ✅ 前端界面 (100%)
- ✅ API接口 (100%)
- ✅ Docker部署 (100%)
- ✅ 技术文档 (100%)
- Built-in API makes it easy to develop applications using your programming language of choice
# app.yml
embeddings:
path: sentence-transformers/all-MiniLM-L6-v2
CONFIG=app.yml uvicorn "txtai.api:app"
curl -X GET "http://localhost:8000/search?query=positive"
- Run local - no need to ship data off to disparate remote services
- Work with micromodels all the way up to large language models (LLMs)
- Low footprint - install additional dependencies and scale up when needed
- Learn by example - notebooks cover all available functionality
The following sections introduce common txtai use cases. A comprehensive set of over 60 example notebooks and applications are also available.
Build semantic/similarity/vector/neural search applications.

Traditional search systems use keywords to find data. Semantic search has an understanding of natural language and identifies results that have the same meaning, not necessarily the same keywords.

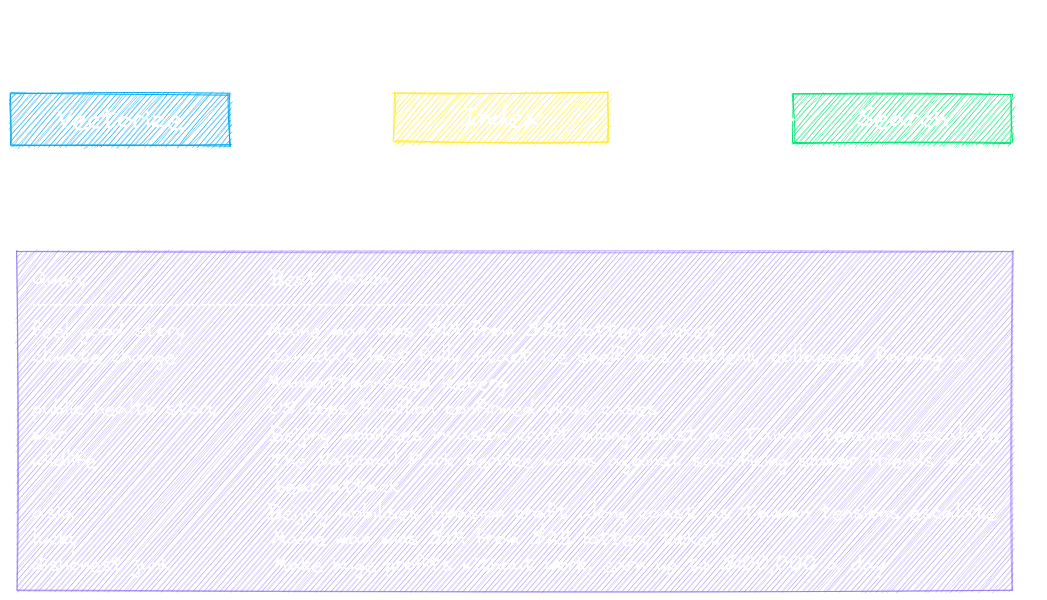
Get started with the following examples.
| Notebook | Description | |
|---|---|---|
| Introducing txtai ▶️ | Overview of the functionality provided by txtai | |
| Similarity search with images | Embed images and text into the same space for search | |
| Build a QA database | Question matching with semantic search | |
| Semantic Graphs | Explore topics, data connectivity and run network analysis |
Autonomous agents, retrieval augmented generation (RAG), chat with your data, pipelines and workflows that interface with large language models (LLMs).
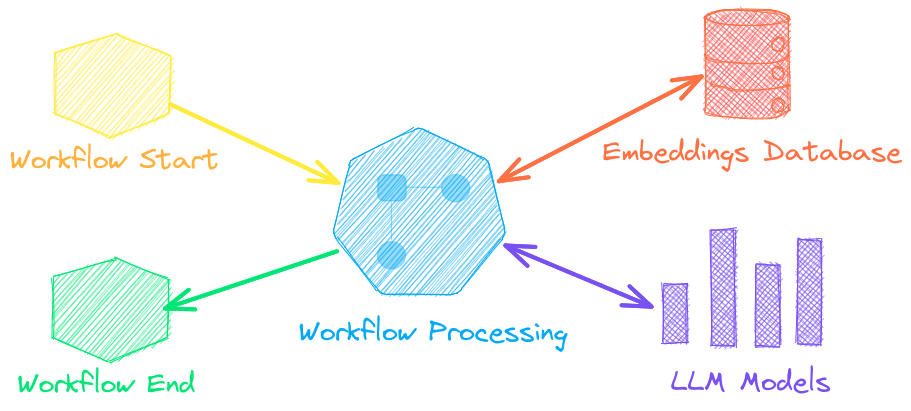
See below to learn more.
| Notebook | Description | |
|---|---|---|
| Prompt templates and task chains | Build model prompts and connect tasks together with workflows | |
| Integrate LLM frameworks | Integrate llama.cpp, LiteLLM and custom generation frameworks | |
| Build knowledge graphs with LLMs | Build knowledge graphs with LLM-driven entity extraction | |
| Parsing the stars with txtai | Explore an astronomical knowledge graph of known stars, planets, galaxies |
Agents connect embeddings, pipelines, workflows and other agents together to autonomously solve complex problems.
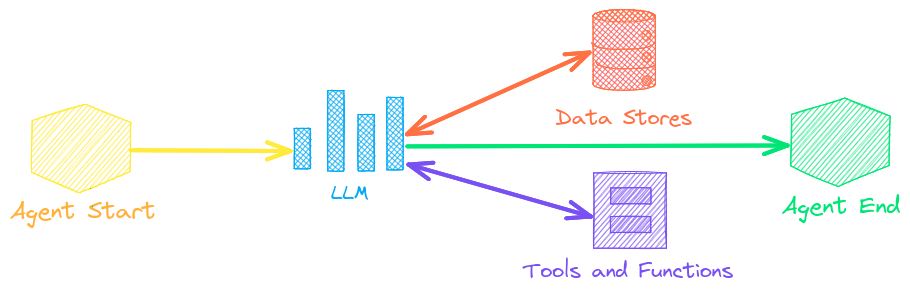
txtai agents are built on top of the smolagents framework. This supports all LLMs txtai supports (Hugging Face, llama.cpp, OpenAI / Claude / AWS Bedrock via LiteLLM).
See the link below to learn more.
| Notebook | Description | |
|---|---|---|
| Analyzing Hugging Face Posts with Graphs and Agents | Explore a rich dataset with Graph Analysis and Agents | |
| Granting autonomy to agents | Agents that iteratively solve problems as they see fit | |
| Analyzing LinkedIn Company Posts with Graphs and Agents | Exploring how to improve social media engagement with AI |
Retrieval augmented generation (RAG) reduces the risk of LLM hallucinations by constraining the output with a knowledge base as context. RAG is commonly used to "chat with your data".


A novel feature of txtai is that it can provide both an answer and source citation.
| Notebook | Description | |
|---|---|---|
| Build RAG pipelines with txtai | Guide on retrieval augmented generation including how to create citations | |
| Chunking your data for RAG | Extract, chunk and index content for effective retrieval | |
| Advanced RAG with graph path traversal | Graph path traversal to collect complex sets of data for advanced RAG | |
| Speech to Speech RAG ▶️ | Full cycle speech to speech workflow with RAG |
Language model workflows, also known as semantic workflows, connect language models together to build intelligent applications.


While LLMs are powerful, there are plenty of smaller, more specialized models that work better and faster for specific tasks. This includes models for extractive question-answering, automatic summarization, text-to-speech, transcription and translation.
| Notebook | Description | |
|---|---|---|
| Run pipeline workflows ▶️ | Simple yet powerful constructs to efficiently process data | |
| Building abstractive text summaries | Run abstractive text summarization | |
| Transcribe audio to text | Convert audio files to text | |
| Translate text between languages | Streamline machine translation and language detection |


The easiest way to install is via pip and PyPI
pip install txtai
Python 3.10+ is supported. Using a Python virtual environment is recommended.
See the detailed install instructions for more information covering optional dependencies, environment specific prerequisites, installing from source, conda support and how to run with containers.
See the table below for the current recommended models. These models all allow commercial use and offer a blend of speed and performance.
Models can be loaded as either a path from the Hugging Face Hub or a local directory. Model paths are optional, defaults are loaded when not specified. For tasks with no recommended model, txtai uses the default models as shown in the Hugging Face Tasks guide.
See the following links to learn more.
- Hugging Face Tasks
- Hugging Face Model Hub
- MTEB Leaderboard
- LMSYS LLM Leaderboard
- Open LLM Leaderboard
The following applications are powered by txtai.
| Application | Description |
|---|---|
| rag | Retrieval Augmented Generation (RAG) application |
| ragdata | Build knowledge bases for RAG |
| paperai | AI for medical and scientific papers |
| annotateai | Automatically annotate papers with LLMs |
In addition to this list, there are also many other open-source projects, published research and closed proprietary/commercial projects that have built on txtai in production.


- Introducing txtai, the all-in-one AI framework
- Tutorial series on Hashnode | dev.to
- What's new in txtai 8.0 | 7.0 | 6.0 | 5.0 | 4.0
- Getting started with semantic search | workflows | rag
- Running txtai at scale
- Vector search & RAG Landscape: A review with txtai
Full documentation on txtai including configuration settings for embeddings, pipelines, workflows, API and a FAQ with common questions/issues is available.
For those who would like to contribute to txtai, please see this guide.