
Today, we're announcing Qwen3-Coder-Next, an open-weight language model designed specifically for coding agents and local development. It features the following key enhancements:
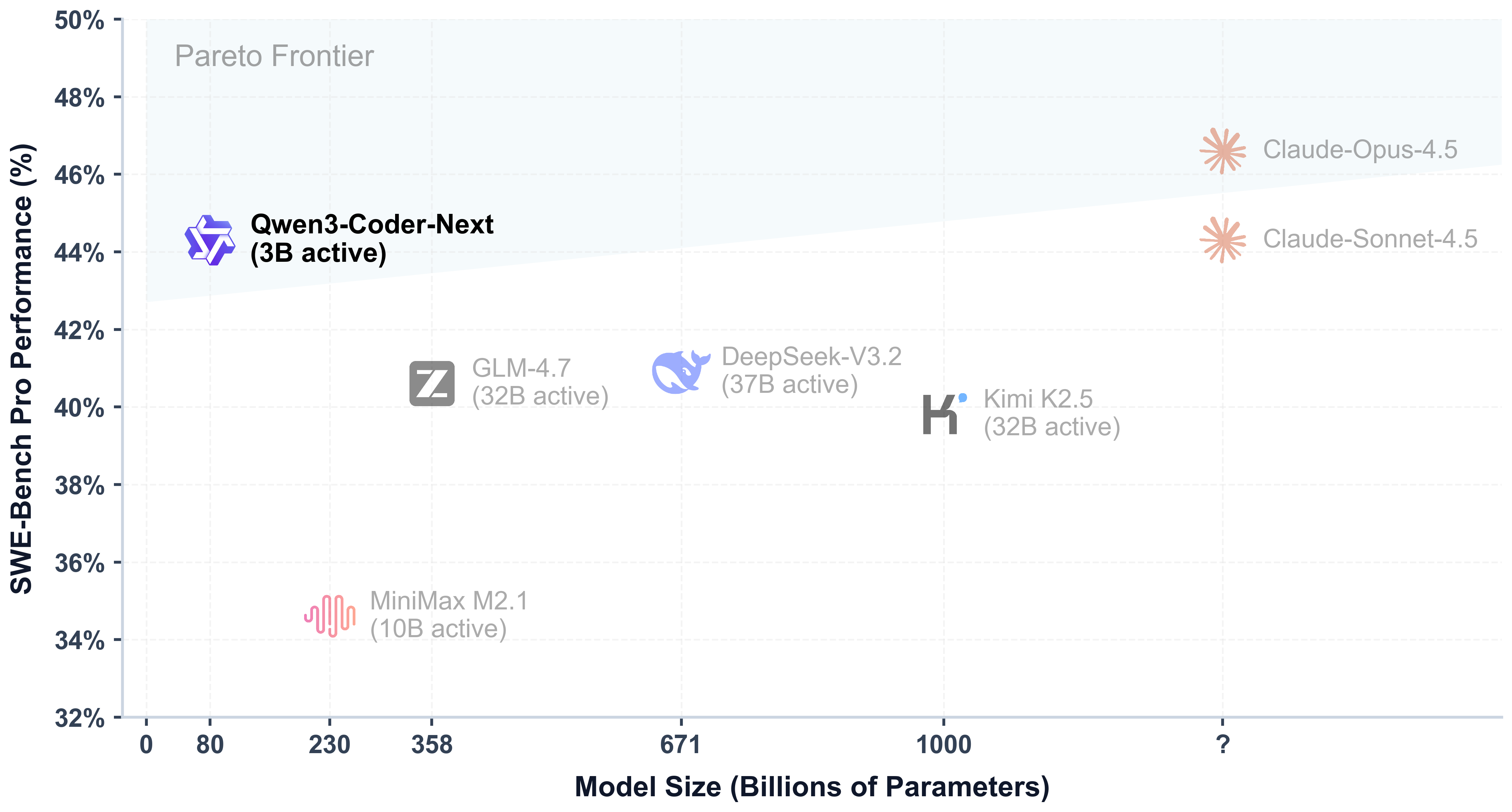
- Super Efficient with Significant Performance: With only 3B activated parameters (80B total parameters), it achieves performance comparable to models with 10–20x more active parameters, making it highly cost-effective for agent deployment.
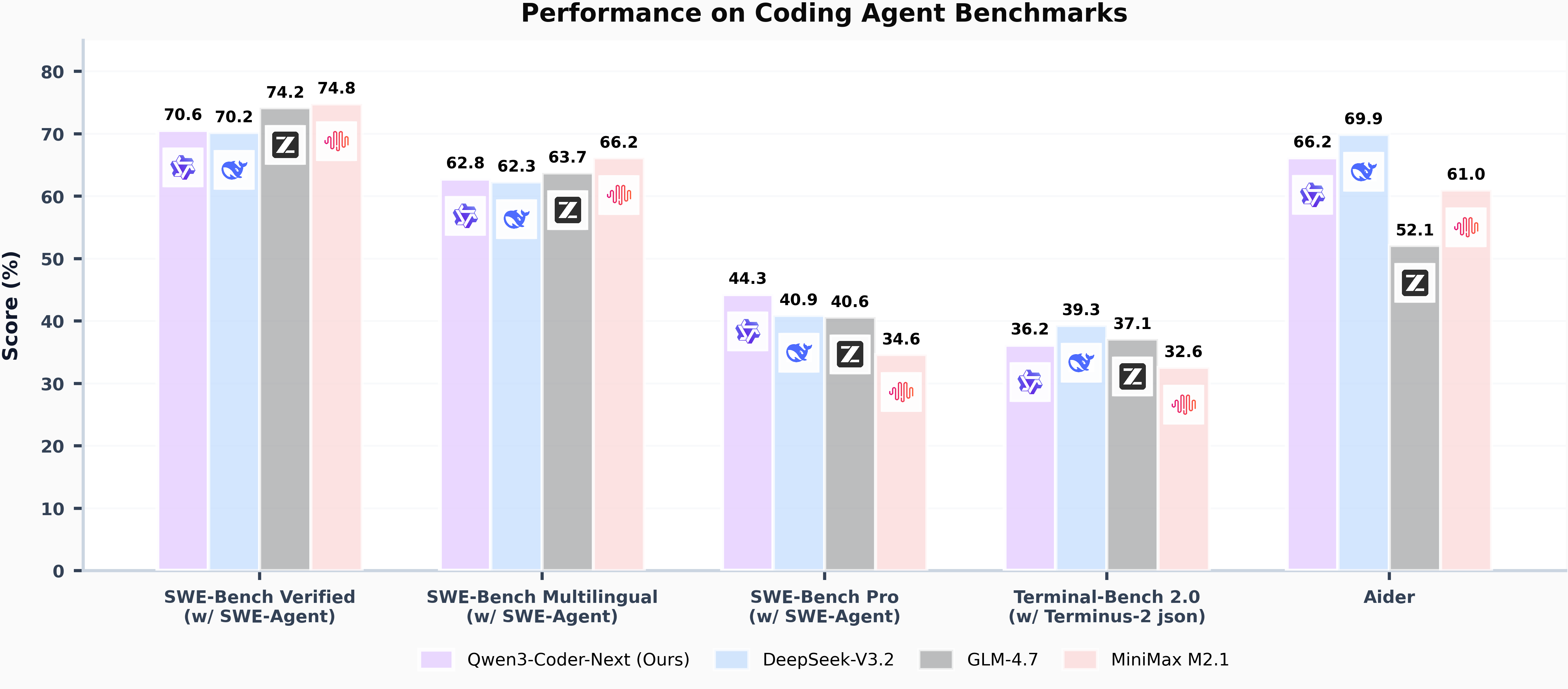
- Advanced Agentic Capabilities: Through an elaborate training recipe, it excels at long-horizon reasoning, complex tool usage, and recovery from execution failures, ensuring robust performance in dynamic coding tasks.
- Versatile Integration with Real-World IDE: Its 256k context length, combined with adaptability to various scaffold templates, enables seamless integration with different CLI/IDE platforms (e.g., Claude Code, Qwen Code, Qoder, Kilo, Trae, Cline, etc.), supporting diverse development environments.
Qwen3-Coder-Next has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 80B in total and 3B activated
- Number of Parameters (Non-Embedding): 79B
- Hidden Dimension: 2048
- Number of Layers: 48
- Hybrid Layout: 12 * (3 * (Gated DeltaNet -> MoE) -> 1 * (Gated Attention -> MoE))
- Gated Attention:
- Number of Attention Heads: 16 for Q and 2 for KV
- Head Dimension: 256
- Rotary Position Embedding Dimension: 64
- Gated DeltaNet:
- Number of Linear Attention Heads: 32 for V and 16 for QK
- Head Dimension: 128
- Mixture of Experts:
- Number of Experts: 512
- Number of Activated Experts: 10
- Number of Shared Experts: 1
- Expert Intermediate Dimension: 512
- Context Length: 262,144 natively
NOTE: This model supports only non-thinking mode and does not generate <think></think> blocks in its output. Meanwhile, specifying enable_thinking=False is no longer required.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our blog, GitHub, and Documentation.
Check out our llama.cpp documentation for more usage guide.
We advise you to clone llama.cpp and install it following the official guide. We follow the latest version of llama.cpp.
In the following demonstration, we assume that you are running commands under the repository llama.cpp.
huggingface-cli download Qwen/Qwen3-Coder-Next-GGUF --include "Qwen3-Coder-Next-Q5_K_M/*"
./llama-cli -m ./Qwen3-Coder-Next-Q5_K_M/Qwen3-Coder-Next-00001-of-00004.gguf --jinja -ngl 99 -fa on -sm row --temp 1.0 --top-k 40 --top-p 0.95 --min-p 0 -c 40960 -n 32768 --no-context-shift
Qwen3 natively supports context lengths of up to 262,144 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the YaRN method.
To enable YARN in llama.cpp:
./llama-cli ... -c 1010000 --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 262144
Qwen3-Coder-Next excels in tool calling capabilities.
You can simply define or use any tools as following example.
# Your tool implementation
def square_the_number(num: float) -> dict:
return num ** 2
# Define Tools
tools=[
{
"type":"function",
"function":{
"name": "square_the_number",
"description": "output the square of the number.",
"parameters": {
"type": "object",
"required": ["input_num"],
"properties": {
'input_num': {
'type': 'number',
'description': 'input_num is a number that will be squared'
}
},
}
}
}
]
from openai import OpenAI
# Define LLM
client = OpenAI(
# Use a custom endpoint compatible with OpenAI API
base_url='http://localhost:8000/v1', # api_base
api_key="EMPTY"
)
messages = [{'role': 'user', 'content': 'square the number 1024'}]
completion = client.chat.completions.create(
messages=messages,
model="Qwen3-Coder-Next",
max_tokens=65536,
tools=tools,
)
print(completion.choices[0])
To achieve optimal performance, we recommend the following sampling parameters: temperature=1.0, top_p=0.95, top_k=40.
If you find our work helpful, feel free to give us a cite.
@techreport{qwen_qwen3_coder_next_tech_report, title = {Qwen3-Coder-Next Technical Report}, author = {{Qwen Team}}, url = {https://github.com/QwenLM/Qwen3-Coder/blob/main/qwen3_coder_next_tech_report.pdf}, note = {Accessed: 2026-02-03} }